Before descending into web scraping with proxies, it’s important to understand what proxies are and how they function. Simply put, a proxy acts as an intermediary between your web scraper and the target website.
Instead of directly connecting to the website, your scraper routes its requests through the proxy server, which then forwards those requests to the website on your behalf. This process effectively hides your scraper’s IP address, providing anonymity and helping to avoid detection or IP bans.
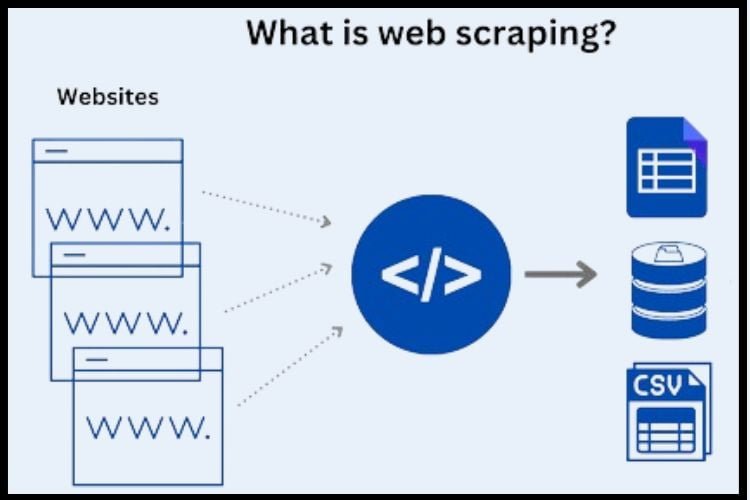
What is web scraping?
Web scraping is the automated process of extracting data from websites. It involves using software programs or scripts to access and gather information from web pages, typically in a structured format such as HTML, XML, or JSON.
Web scraping enables users to recover large amounts of data from the internet quickly and efficiently, which can then be analyzed, processed, and utilized for various purposes such as market research, competitive analysis, price monitoring, and more.
Why Use Proxies for Web Scraping?
1. Anonymity
Proxies mask your IP address, making it difficult for websites to identify and block your scraping activities.
2. Scalability
With proxies, you can distribute your scraping workload across multiple IP addresses, allowing you to scrape larger volumes of data without starting rate limits or getting banned.
3. Geolocation
Proxies offer the flexibility to scrape data from different regions by routing your requests through servers located in various geographic locations.
4. Reliability
By rotating proxies, you can mitigate the risk of getting blocked by websites that employ IP-based restrictions or anti-scraping measures.
How to Scrape with Proxies
1. Choose a Reliable Proxy Provider
Look for reputable proxy providers that offer a diverse range of IP addresses, rotating proxies, and reliable uptime.
2. Configure Your Scraper
Integrate proxy support into your scraping script or tool. Most scraping libraries and frameworks provide options for specifying proxy settings.
3. Rotate Proxies
Implement a rotating proxy strategy to switch between different IP addresses periodically.This helps prevent detection and ensures continuous scraping.
4. Monitor Performance
Keep an eye on your scraping performance, including response times, success rates, and error logs. Adjust your proxy settings as needed to optimize performance.
5. Handle Captchas and Rate Limits
Be prepared to handle challenges such as captchas and rate limits, which may arise when scraping with proxies. Use techniques like CAPTCHA-solving services or delays between requests to overcome these limitations.
Understanding Different Types of Proxies
1.Private Proxies
Private proxies, as the name suggests, are dedicated solely to a single user. They offer exclusive access to an IP address, providing enhanced anonymity and reliability. Private proxies are ideal for high-security applications and sensitive scraping tasks where IP integrity is important.
2.Shared Proxies
Shared proxiesare used by multiple users simultaneously. While they are more affordable, shared proxies may experience higher traffic and slower speeds due to the shared nature of the IP address. However, they remain a possible option for less demanding scraping tasks and budget-conscious users.
Conclusion
InProxiesforrentWeb scraping with proxies opens up a world of possibilities for accessing and extracting data from the web. By leveraging proxies effectively, you can enhance the efficiency, reliability, and scalability of your scraping operations while maintaining anonymity and avoiding detection. Whether you’re gathering market intelligence, monitoring competitor activity, or extracting valuable insights, mastering the art of web scraping with proxies is a valuable skill for any data-driven professional.
Web scraping involves extracting specific data from web pages, while web crawling refers to the automated process of browsing and indexing web pages to build a database or search engine index.
To avoid getting blocked, use techniques such as rotating user agents, limiting the frequency of requests, and using proxies to distribute requests across multiple IP addresses.
Ethical considerations surrounding web scraping include obtaining data legally, respecting website terms of service, and ensuring the privacy of individuals’ information.
Web scraping can extract data in various formats, including HTML, JSON, XML, CSV, and more. The choice of format depends on the structure of the data being scraped and the requirements of the scraping task.
Common challenges in web scraping include handling dynamic content, dealing with anti-scraping measures such as CAPTCHAs and rate limits, and maintaining the reliability and scalability of scraping scripts.