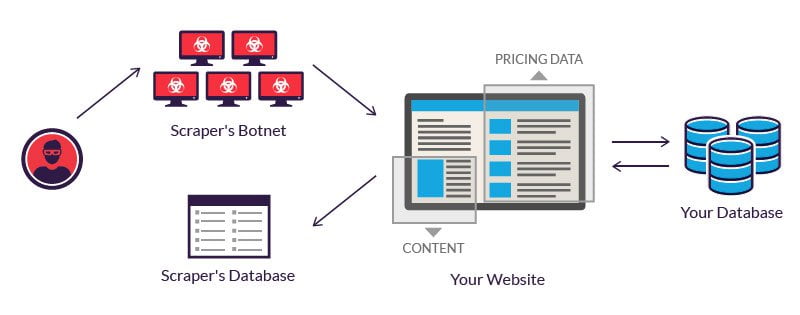
Web scraping, also known as web harvesting or web data extraction, is the automated process of extracting information from websites. It involves fetching and parsing HTML code to collect data from web pages, which can then be analyzed, manipulated, and stored for various purposes.
How Does Web Scraping Work?
Web scraping can be done manually, but it’s often automated using software tools called web scrapers or crawlers. These tools send HTTP requests to the target website, retrieve the HTML content, and then parse it to extract the desired data. The extracted data can then be saved in a structured format like CSV or JSON for further analysis.
The Role of Proxies in Web Scraping
Proxies play a vital role in web scraping by masking the IP address of the scraper and providing anonymity while accessing websites. There are two main types of proxies used in web scraping: private proxies and shared proxies.
Private proxies offer dedicated IP addresses, ensuring high anonymity and reliability, while shared proxies provide multiple users with access to the same IP address, offering a cost-effective solution for scraping tasks. Platforms like Proxiesforrentoffer a range of proxy solutions tailored to the specific needs of web scrapers, providing reliable infrastructure for data extraction projects.
Applications of Web Scraping
1. Market Research
Businesses use web scraping to gather data on competitors, market trends, and consumer behavior, enabling them to make informed decisions.
2. Lead Generation
Sales and marketing teams employ web scraping to gather contact information from websites, generating leads for outreach campaigns.
3. Price Monitoring
E-commerce platforms use web scraping to monitor competitors’ prices and adjust their pricing strategies accordingly.
4. Content Aggregation
News aggregators and content platforms scrape data from multiple sources to curate and deliver relevant content to users.
5. Academic Research
Researchers utilize web scraping to collect data for studies, analyze trends, and gain insights into various fields.
6. Storing or Using Data
Finally, the extracted data can be stored in a database, spreadsheet, or any other format for further analysis or processing.
Conclusion
Web scraping represents a powerful tool for extracting valuable data from the vast expanse of the internet. With its ability to automate data collection and analysis, web scraping enables businesses to gain insights, make informed decisions, and drive growth.
By leveraging proxies such as private proxies and shared proxies, web scrapers can enhance their anonymity and reliability, ensuring seamless execution of scraping tasks. As technology continues to evolve, the potential of web scraping to revolutionize industries and drive innovation remains unparalleled.
While web scraping itself is a legitimate technique, it can be abused for malicious purposes such as data theft, spamming, and unauthorized access to sensitive information. It’s important to use web scraping responsibly and ethically.
Websites can often detect web scraping activity through various means such as analyzing user-agent strings, monitoring IP addresses, and implementing CAPTCHA challenges. It’s important to scrape responsibly and avoid overloading a website’s servers.
Platforms like Proxiesforrent offer a range of proxy solutions tailored to the specific needs of web scrapers. They provide reliable infrastructure, diverse IP pools, and responsive support, ensuring seamless execution of scraping tasks with maximum anonymity and efficiency.
Proxies provide anonymity, bypass IP-based restrictions, and help distribute scraping requests across multiple IP addresses, reducing the risk of detection and blocking.
Proxies are not strictly necessary for web scraping, but they play a crucial role in maintaining anonymity, bypassing restrictions, and optimizing performance, especially for larger scraping projects or tasks requiring high reliability.
Proxies play an important role in web scraping by masking the IP address of the scraper, ensuring anonymity, and preventing IP bans from websites. They also help distribute scraping requests across multiple IP addresses, minimizing the risk of detection and blocking.